Nachtrag von OpenRefine
Validierung XML: MARCXML-Schema definiert Regeln für XML-Dateien. Wenn man saubere XML-Daten produzieren möchte, muss das unbedingt abgeglichen werden. Es wird ein XSD-Format genutz, um ein Schema zu definieren für XML-Daten. Was soll wann vorkommen und wie soll es aussehen? Das Schema kann die Form vorgeben und validieren, aber auch Inhalte im Feld vorgeben. Die Prüfung der Form soll mindestens sichergestellt werden, wenn man XML-Dateien geschrieben hat. Validierung ist eine wichtige Grundlage.
Template exportieren, abspeichern und dann im Skript verschiedene Möglichkeiten der Validierung.
wget https://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd
xmllint *.xml --noout --schema MARC21slim.xsd
XML-Deklaration
Bei der XML-Deklaration handelt es sich um eine zusätzliche Textzeile am Anfang der XML-Datei:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>.
Durch diese Zeile erhält die Software den Hinweis, dass es sich um XML handelt. Die Software muss also nicht erst die ganze Datei einlesen und alles prüfen, das ist vor allem bei grossen Dateien hilfreich.
Mit der Codezeile zu Beginn sagen wir: Es ist XML und wir sagen, welche Version (es gibt 1.0 und 1.1), encoding meint, in welcher Zeichencodierung wir das gespeichert haben. Sonderzeichen Umlaute u.ä. werden im Zeichensatz direkt abgebildet.
Standalone klärt, ob die Dokumenttypdefinition in der Datei selbst beiliegt. Standalone yes bedeutet, dass die Dokumenttypdefinition (DTD) integriert ist, no heisst, es gibt eine, allerdings muss die noch extern abgefragt werden. Wenn das Attribut standalone weggelassen wird, gilt die Standarddokumenttypdefinition von XML. Wenn wir Standalone angeben, muss die Versionangabe beiliegen, zusätzlich dazu encoding anzugeben, ist nicht verpflichtend aber gute Praxis.
Standalone kommt in Praxis nicht häufig vor. Die Reihenfolge der Attribute ist festgelegt und kann nicht geändert werden. Merci vielmals für diese Erklärung, denn das sieht man ja häufiger und bis anhin habe ich mir über die Bedeutung eigentlich noch keine Gedanken gemacht, obwohl das ja schon wichtig ist.
Was mich noch beschäftigt ist folgendes: Dokumenttypdefinition wäre ja eine DTD. Ich gehe aber davon aus, dass das Attribut standalone auch für das XML-Schema XSD gilt, ich habe einige Quellen gefunden, wo das standalone-Attribut in Verbindung mit XSD genutzt wurde. Im Gegensatz zur DTD ist XSD etwas “genauer”, respektive die geforderten Inhalte von Tags und Attributen können genauer angegeben werden und es ist selbst XML-basiert und verwendet keine separate Syntax wie DTDs. XSD-Dokumente bestehen selbst immer aus wohlgeformten XML-Dokumenten (Kersken, 2020).
Alternativen zu OpenRefine
Es gibt natürlich alternative Software zu OpenRefine, generell gilt, dass die Software anhand des Anwendungsfalls gewählt werden sollte. In der Praxis wählt man das, was man schon gut kann, dafür wird es dann manchmal sehr umständlich. Catmandu und Metafacture ist programmierlastiger, OpenRefine hat hingegen eine wunderbare graphische Oberläche.
JSON-APIs
In der normalen Internetumgebung haben wir meistens mit Programmierschnittstellen zu tun, die JSON ausliefern. Es gibt aber auch immer mehr bibliothekarische Schnittstellen, die mit JSON arbeiten, denn JSON lässt sich gut parsen und aus- und verwerten.
LIDO
Lido: Lightweight Information Describing Objects basiert auf CIDOC-CRM (Conceptual Reference Model). Es handelt sich dabei um einen XML-Standard vor allem für Kulturobjekte und ist in Museen stark verbreitet. Lido ist etwas anders geartet als alle anderen Metadatenstandards und im Prinzipt eine vereinfachte XML-Version von CIDOC-CRM.
CIDOC selbst ist eine Vereinigung von Museen und deren Experten. CIDOC-CRM ist sehr abstrakt, nicht für die direkte Anwendung gedacht, sondern eher Modell für Standards und Metadatenableitung. Es definiert Konzepte und Relationen, die dann verwendet werden können. Konzepte sind beispielsweise Entitäten (Dinge die ich beschreiben kann) und Relationen (Beziehungen, die Entitäten haben können). Alles wird mit eindeutigen URIs identifiziert und entspricht somit dem Linked Data-Paradigma. Dies erlaubt Querverweise zu anderen Institutionen, Objekten usw.
Die Struktur ist recht speziell, denn Lido ist ereigniszentriert, bisher hatten wir ja nur mit dokumentzentrierten Standards zu tun.
Da ich bei Entitäten und Relationen automatisch an Datenbankmodelle denke, kann ich mir das glaube ich relativ gut vorstellen.
Objekte können Ereignis teilen, wodurch sie miteinander in Verbindung stehen. Auch Werkzeug und Werk können so in Beziehung stehen, da sie durch das Ereignis der Entstehung miteinander verbunden sind. Nachteil ist jedoch, dass die Überführung in andere Standards beinahe unmöglich ist. Ein Crosswalk ist kaum verlustfrei möglich, denn die Informationen können zwar übernommen werden, allerdings gehtdas Beziehungsgeflecht verloren.
LIDO Struktur:
- deskriptive Metadaten:
- Identifikation (Titel/Name, Beschreibung, Masse etc.)
- Klassifikation (Art, Gattung, Form usw.) -> müssen CIDOC-CRM entsprechen.
- Ereignisse (Herstellung, Bearbeitung, Besitzwechsel, Restaurierung etc.)
- Relationen (Objekte, Personen, Orte usw.)
- administrative Metadaten:
- Rechte (Objekt, Datensatz, Nutzung, Verbreitung…)
- Datensatz (Identifikation, Urheber*in…)
- Resssourcen (Digitalisat, Nachweis…)
Spannend ist auch der Unterschied zwischen Display und Index-Elements: Bei der Erschliessung muss man sich auch gleich Gedanken machen, wie Daten auf der (Benutzer-)Oberfläche aussehen sollen. Für jede Angabe, die man macht, kann man unterscheiden zwischen technischer, interner Form und Anzeigeform.
Bisher fungierte Lido eher als Austauschformat, ansonsten arbeiten Museen immer noch eher dokumentzentriert.
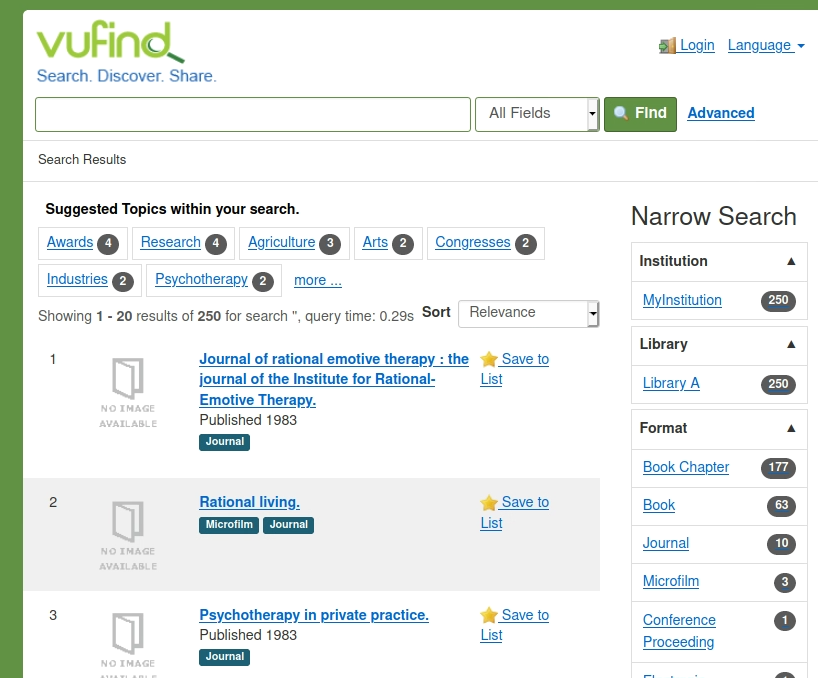
VuFind Installation
VuFind gibt es schon recht lange, die Entwicklung wird aber vor allem von einigen wenigen Personen vorangetrieben. Bei OpenHub kann man sich generell einen Überblick verschaffen. Vufind ist eine php-Software, die eine Datenbank (MariaDB) und für die Suche solR verwendet. Letztere müssen wir manuell starten, während Datenbank im Hintergrund bereits läuft.
Die Installation von Vufind hat mir einiges abverlangt! Dank der guten Anleitungen und minimaler Shell-Erfahrung, die ich mir in vorherigen Modulen angeeignet habe, haben alle Installationen bisher wunderbar geklappt und ich konnte 99% davon auch nachvollziehen. Trotzdem ging dieses Mal einiges schief. Beim Installationstermin musste ich früher weg und habe die Installation deshalb dann nicht beendet, wohl aber angefangen. Als ich das dann später nachholen wollte, scheiterte ich an mehreren Problemen:
-
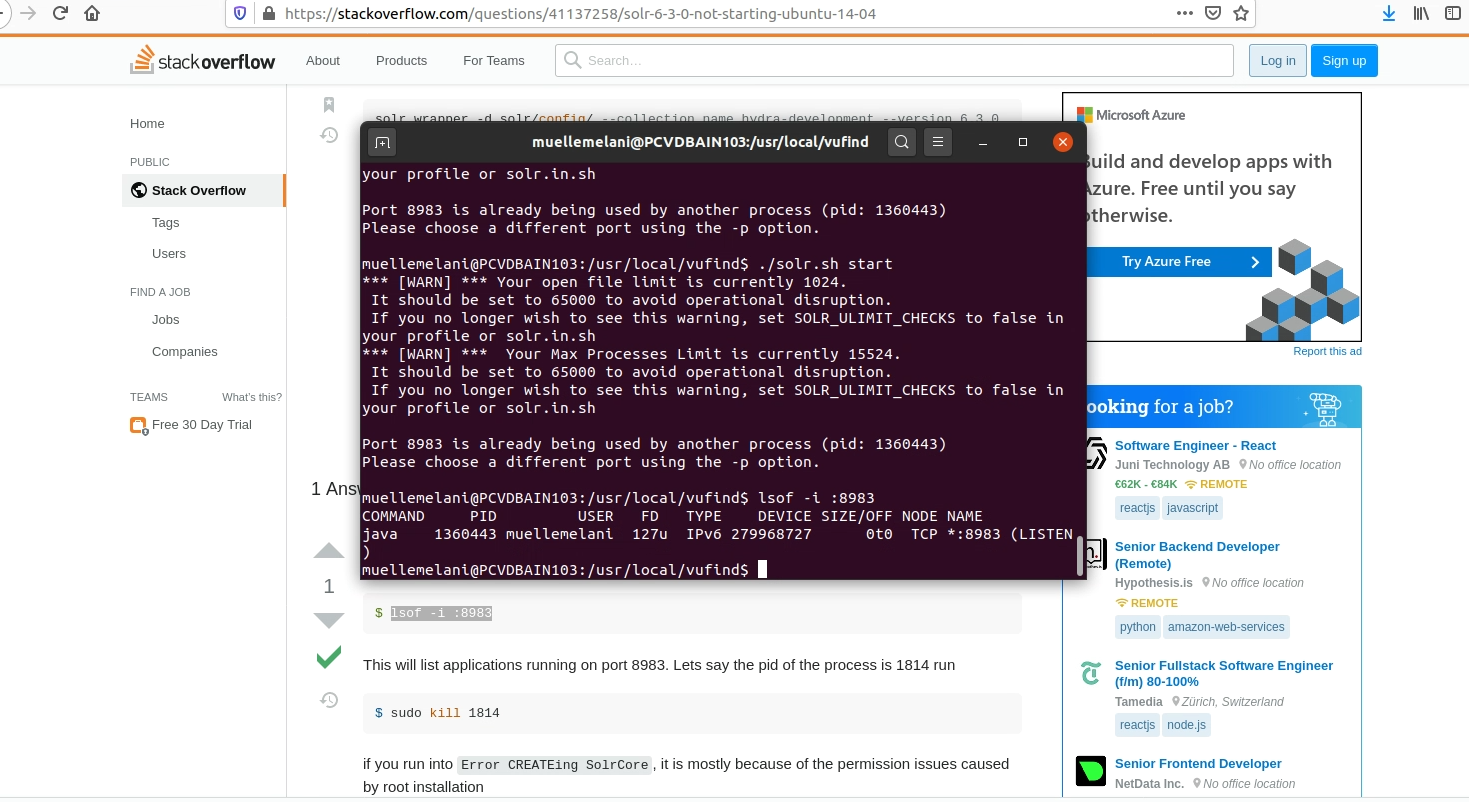
Beim Start von solr hiess es, der Port sei schon besetzt. Eine kurze Google-Suche später wusste ich, was zu tun ist:
sudo kill [process-pid]
Danach konnte solr normal gestartet werden
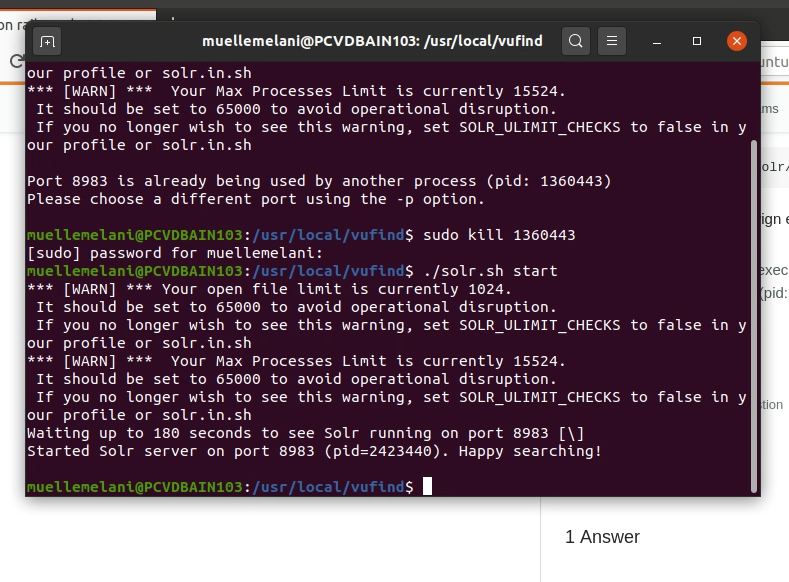
- Nächstes Problem: Error 404 beim Aufrufen von http://localhost/vufind/Install/Home. Alles klar, also nochmals von vorne alles neu installiert. Zwischenzeitlich war ich unsicher, ob tatsächlich Java 8 installiert war, deshalb habe ich das überprüft mit
Java -version. So ganz schlau geworden daraus bin ich nicht, aber in der Versionsnummer war eine 8 enthalten, deshalb dachte ich, dass das schon passen wird. Auch nach der Neuinstallation trat das Problem auf, dass solr nicht gestartet werden konnte, aber das war ja inzwischen kein Hindernis mehr. Und siehe da, die Seite liess sich mit der Neuinstallation tatsächlich aufrufen. Problem gelöst. - Die nächste (und mühsamste) Stolperfalle war dann der Import der Dateien im MARC21-Format. Dies liess sich nicht bewerkstelligen, ganz egal, wie ich das versucht habe. Am Ende dämmerte es mir dann doch: Da war doch was mit einem Befehl, der in der ersten Version der Anleitung nicht richtig ausgeführt worden war… Doch wie reparieren? Ich habe dann mal bei meinen Kolleginnen und Kollegen in den Lerntagebüchern gespickt, um zu schauen, wie die das gelöst haben und natürlich wurde ich bei Gaby Leuenberger fündig:
sudo apt-get update
sudo apt-get upgrade
Dann Java 8 installieren:
sudo apt install -y openjdk-8-jdk
Alle Schritte gemäss Anleitung bis und mit dem Starten von Solr nochmals durchgeführt und wow, schon läufts wie geschmiert. Alle Konfigurationsschritte auf http://localhost/vufind/Install/Home konnte ich mir sparen, da ich das schon durchgeführt hatte. Nun klappte auch der Import der Beispieldaten problemlos: