Isn’t it true that only librarians like to search? Everyone else likes to find. (Tennant, 2001)
Solr und VuFind
Wir erarbeiten heute die Funktionen von Suchmaschinen am Beispiel von Solr. Solr nutzen wir mit Vufind (Discovery-System), da Solr selber keine Website mitgeliefert hat, nur Admin-Oberfläche. Solr ist mit Elasticsearch quasi “Industriestandard” und damit eine der meistbenutzen Suchmaschinen im Internet und bei Volltextsuchen. Solr ist auch ausserhalb des Bibliotheksbereichs interessant.
Üblicherweise soll vor Import der Daten in einem Schema festgelegt wreden, welche Felder existieren und welche Datentypen diese beinhalten dürfen. Ungenauigkeiten können so beim Import festgestellt werden. Was soll überhaupt durchsucht werden? Diese Frage wird vorher optimalerweise geklärt. Trotzdem gibt es inwzischen auch das schemaless-Vorgehen, es wir also ohne Schema gearbeitet. solr versucht, die Daten so gut wie möglich zu übernehmen.
Solr hat eine integrierte Suchoberfläche in der Adminoberfläche, zum Nachstellen der Suche gibt es auch eine Demowebsite. Allerdings ist die wirklich nur zu Testzwecken gedacht. Viele komerzielle Produkte basieren auf solr, wie beispielsweise Ex Libris Primo. Auch Vufind basiert auf Solr.
Unterschiede Suchindex und Datenbank
Zur genaueren Unterscheidung zwischen Datenbank und Suchindex haben wir uns die beiden Systeme anhand konkreter Beispiele etwas genauer angeschaut. Grundsätzlich wird beides mit Daten gespeist, jedoch haben die Systeme unterschiedliche Schwerpunkte.
| Solr | MySQL |
| flache Dokumente (keine Beziehungen innerhalb des Index) | relationale Datensätze |
| lexikalische Suche (Begriff wird mit Grammatik verstanden und dementsprechend behandelt, beispielsweise Verben auf Grundform brechen und dann sinngemäss suchen) | reiner Glyphenvergleich (Vergleichen, was in der Datenbank steht wortwörtlich) |
| keine Konsistenzprüfung (Suchindex hat keine Kontrolle über Konsistenz, nicht geeignet für persistente Datenspeicherung) | Transaktionssicherheit (Abbruch der Übertragung usw. hat keine Auswirkung auf Datenstand) |
| statische Daten | veränderliche Daten |
| Retrieval (suche) | Storage (CRUD, Create, Read, Update, Delete) |
Übung 1:
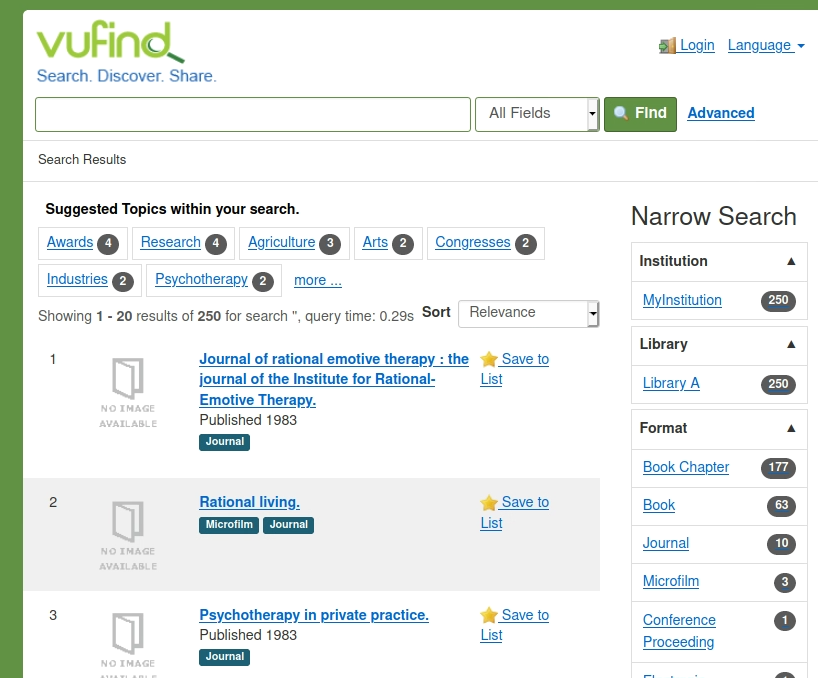
Wir führen zweimal die gleiche Suchanfrage aus, einmal in der Adminoberfläche von Solr und einmal im Discoverysystem Vufind.
Über das Discoverysystem Vufind können nur ausgewählte Felder angegeben werden, vieles kann gar nicht genau angegeben werden (beispielsweise Publishdate, was über die Adminoberfläche von solr geht).
Die Suchanfrage über Solr direkt gibt JSON aus. Die Darstellung über Vufind ist natürlich sehr viel schöner und allgemeinverträglicher.
Das Logfile für die Suche über VuFind ist sehr viel länger. Zudem gibt es dort eine Autovervollständigung, wodurch immer wieder für jeden Buchstaben ein neues Logfile generiert wird. Die ^zahlen verdeutlichen die Gewichtung

Mit allfields:1983 in Solr wurden drei Treffer erzielt (hits=3). Ein Gewichtung bei der solr-Suche direkt ist im Logfile nicht erkennbar. Da stellt sich mir die Frage, wird bei Suchen in der Adminoberfläche also gar keine Gewichtung vorgenommen?

Es gab wohl Versuche, Personalisierungen bei der Gewichtung durchzuführen, so dass beispielsweise Kunststudent*innen ein anderes Ranking erhalten als Maschinenbauer*innen. Das hat aber nicht wirklich so funktioniert, wie das beispielsweise bei Google klappt. Ein Problem ist auch, dass Suchvorgänge so nicht mehr wirklich reproduzierbar sind.
Nach dieser Übung haben wir sämtlichen importierte Daten gelöscht (was nach dem mühsamen Troubleshooting vom letzten Mal kurzzeitig Schnappatmungen bei mir ausgelöst hat, siehe dazu den Blogbericht vom letzten Mal).
Übung 2:
Der Import mit Koha und doaj hat problemlos geklappt, wie angekündigt ging es mit Archivesspace und DSpace nicht. Dies lag daran, dass solr gemäss Schema ein Unique-Key verlangt, welcher bei MARC21 lediglich optional ist. Als Lösung lässt sich händisch eine ID für das Feld 001 vergeben oder über OpenRefine einfügen.
Meine Idee wäre ja gewesen, dass Schema.xml abzuändern und den Unique Key zu löschen. Das habe ich versucht, hat aber nicht geklappt, und da ich diesen Lösungsweg auch online nicht gefunden habe, gehe ich davon aus, dass das wohl nicht die eleganteste (oder grundsätzlich erlaubte) Lösung ist. Mit dem vorgeschlagenen Lösungsweg, die Dateien händisch abzuändern, hat das jedoch geklappt.
Was ich auch noch versucht habe, war, nach dieser Anleitung automatisch eine ID vergeben zu lassen. Das hat aber leider auch nicht funktioniert, ich vermute, dass mir Plugins fehlen(?) oder dass ich das Teilcodestück einfach am falschen Ort eingefügt habe. Da das aber aufgrund von Dubletten wohl ohnehin nicht so praktisch ist, habe ich das dann nicht weiter verfolgt.
Marktüberblick Discovery Systeme
Wir haben in einem früheren Termin schon über den Library Systems Report gesprochen, da gab es jetzt nochmachls einen Überblick. Wir haben bis anhin vor allem über integrierte Bibliothekssysteme gesprochen. Discovery Systeme gibt es aber auch. Primo von Exlibris ist dabei Marktführer. In der Schweiz wurde ExLibris Alma und damit das dazu gehörige Discovery-System Primo VE eingeführt. Im Vergleich ist Vufind gar nicht so schlecht, denn die Funktionalitäten unterscheiden sich nicht gross. Ein weiterer wichtiger Punkt ist die Frage der Daten: In grossen Discoverysystemen wird bereits eine grosse Datenmengen mitgeliefert.
Central Index: Nachfolger von Aleph und Co können E-Ressourcen besser verwalten. Pakete müssen an- und abgeschaltet werden können. Häufig hat man einen grossen Index, also Suchindex, den man mitkauft, damit man in Discovery-Oberfläche oder E-Ressourcen-Management-Tool Zugriff hat auf Info, was es überhaupt gibt. Wenn man ein Discoverysystem macht, kauft man in der Regel Software und gleichzeitig Index dazu, bei Primo wäre das Primo Central. Ein Discoverysystem ohne Arikelindex bringt im Prinzip nicht mehr sooo viel.