OpenRefine Tutorial
OpenRefine: Freies Open Source Tool um mit “Messy Data” zu arbeiten.
- grafische Oberfläche, ähnelt klassischer Tabellenverarbeitungssoftware
- dient der Analyse, Bereinigung, Konvertierung und Anreicherung von Daten
- wird in der Regel lokal auf einem Computer installiert und im Browser bedient, aber auch auf Server. Hat aber keine Personenverwaltung und dementsprechend keinen Schutz, benötigt also organisatorische Absprachen, um Programm wirklich zu nutzen.
Wofür ist OpenRefine?
- Überblick über Daten verschaffen
- Inkonsistenzen in Datensets lösen und entdecken, beispielsweise Datenformat standardisieren
- Datensätze aufsplitten
- Datensets matchen
- Datenset mit Fremddaten anreichern
- Abgleich mit Normdaten
Gemäss unregelmässigen Umfragen von OpenRefine wird das Tool vor allem für die Normalisierung von Daten genutzt. Zweiter Punkt ist für Datentransformation. Seltener wird es auch noch genutzt, um Daten in anderes System zu laden, fremden Daten zu verstehen und um Daten anzureichern.
Dementsprechend ist OpenRefinde besonders geeignet für tabellarische Daten (CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreichen) aber auch einfaches flaches XML (MARCXML) oder JSON ist mit etwas Übung noch relativ einfach zu modellieren. Komplexeres XML mit Hierarchien (beispielsweise EAD) ist möglich mit Zusatztools. Kann auch in Kombination mit MarcEdit für Analyse und Transofmration von MARC21 benutzt werden.
erstes Arbeiten mit OpenRefine
Bei OpenRefine gibt es zwei Darstellungsoptionen: Rows und Records. Rows repräsentieren einzelne Records und im Record-Mode werden verschiedene Rows angezeigt, die zum gleichen Record gehören. Zellen können gesplittet/gejoint werden. Dazu Seperator gut auswählen, dieser darf nicht im Datenset enthalten sein! Als Excel-Userin zuerst ungewöhnlich, werden Funktionen direkt bei der jeweiligen Spaltenbeschriftung angegeben. Macht aber eigentlich Sinn und ist intuitiv.
Zum Filtern unterscheidet OpenRefine zwischen Facets und Filtern
Facets: helfen, einen Überblick über die Daten zu verschaffen und Konsistenz zu verbessern. Sie “gruppieren” bestimmte Werte, welche dann über das Panel in- (oder danach auch wieder ex-)kludiert werden können. Die “Gruppierungen” können über edit auch bearbeitet (und so beispielsweise zusammengefügt oder vereinheitlicht) werden. Neben den Text-Facets gibt es auch noch
- Numeric Facets
- Timeline facets (für Daten)
- Scatterplot Facets
- Custom Facets
Die erste beiden kreieren einen Art Schieberegler, wo dann das Datum respektive die Zahl eingeschränkt werden kann. die Custom Facets beinhalten viele Arten von Facets. Häufig gebraucht wird wohl Facet by Blank und Text length Facet. Facet by Blank beispielsweise unterteilt die Daten danach in true (also blanket vorhandan - true, ja) und false.
Filter hingegen sind für bestimmte Textteile, vergleichbar mit CTRL+F. Für die Filter können auch Regex-Expressions gewählt werden. Da Regex und ich bin anhin nicht die besten Freunde wurden, wird mir das wohl nicht so schnell passieren…
Eine weitere mächtige Funktion von OpenRefine stellt das Clustering dar. Dies wir benutzt, um ähnliche, aber inkonsistente Daten in einer Spalte zu mergen. Offenbar gibt es verschiedene Merging-Methode, welche am besten funktioniert, ist logischerweise vom Datensatz abhängig. Leider hat bei mir nur die key collision (fingerprint)-Methode funktioniert, etwas anderes konnte ich nicht anwählen.
Beim Dropdown-Menü auf der ersten Spalte (all) können Spalten entfernt, anders angeordnet oder umbenennt werden.
GREL
GREL ist das Akronym für General Refine Expression Language. Mit Facets, Filtern und Clustern können wir bereits einiges an den Daten verändern. Trotzdem gibt es einige Dinge, die sich dadurch nicht erreichen lassen, beispielsweise mehrere Spalten aus einer machen, Daten standardisieren, ohne sie sinngemäss zu verändern oder bestimmte Teile der Datensätze zu extrahieren. Dafür braucht es “Transformations”. Für Transformations gibt es eine spezielle Sprache, genannt GREL. Es gibt beispielsweise
| value.toUppercase() | schreibt alles gross |
| value.toLowercase() | schreibt alles klein |
| value.toTitlecase() | erster Buchstabe gross, Rest klein |
| value.trim() | trimmt String/wert |
| value.toDate(“dd/MM”yyyy”) | gibt Datenformat an |
| value.toString(“dd MMMM yyyy”) | wandelt Datum in String nach vorgegebenen Format um |
| value.contains(“test”) | liefert Boolean Ausdruck zurück |
| if(value.contains(“test”), “Test data”, value) | ersetzt einen Zellenwert mit den Worten “Test Data” wenn der Wert in der Zelle den tring “test” irgendwo beinhaltet. |
In OpenRefine gibt es auch Arrays. Diese sind Listen von Werten, die wie gewohnt in [] präsentiert werden. Die Werte werden jeweils von “” abgeschlossen (bei Strings) und durch Kommas getrennt. Mit GREL-Expressions können Arrays transformiert werden:
| value.split(“,”) | trennt bei Komma |
| value.split(“,”).sort() | würde das splitten und alphabetisch sortieren A-Z |
| value.split(“,”)[0] | gibt ersten Listeneintrag aus |
| value.split(“,”).sort().join(“,”) | würde Array wieder zusammenführen, allerdings ist der Eintrag dann alphabetisch sortiert. |
Daten, die mit OpenRefine bearbeitet wurden, können am Ende exportiert werden.
Fetching und Reconciling
Fetching from URL: Daten können von Schnittstellen abgefragt und genutzt werden. Wir haben im Beispiel JSON importiert als eine Spalte und dann mit der Funktion parseJson() bestimmte Bestandteile ausgelesen und in eine neue Spalte integriert. Dies ist in zwei Schritten passiert, ich habe versucht, das ganze auch in einem Schritt zu machen, das hat aber leider nicht geklappt. Ein guter Tipp: JSON-Daten können auch im Browser dargestellt werden. Im Zweifelsfall lieber dort einmal die Baumstruktur ansehen, dann ist schon vieles klarer als im mini-OpenRefine-Fenster.
Reconciling: Daten von unseren Daten können mit externen Services abgeglichen werden. Da wir aber zu diesem Thema noch eine Hausaufgabe haben, vertiefe ich das heir nicht weiter.
Übungen
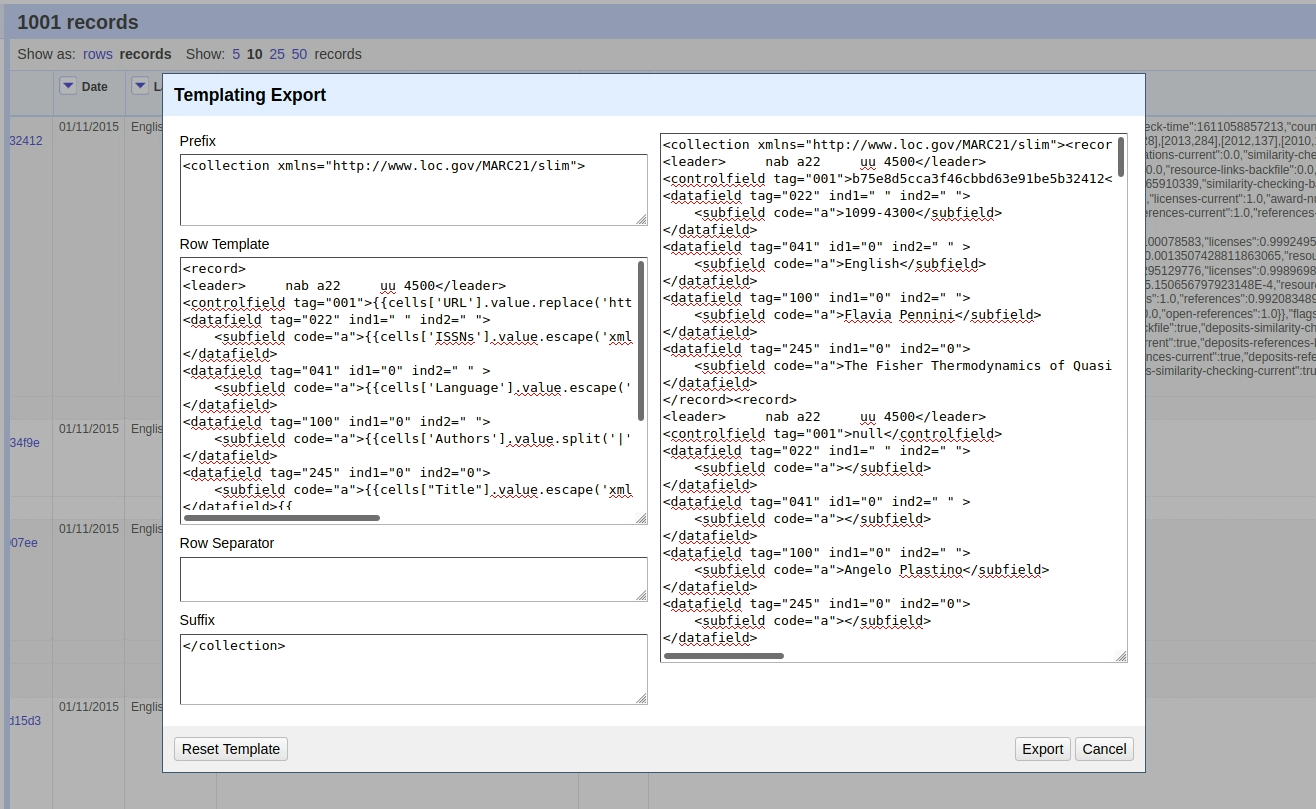
Wir nutzen die Funktion Templating Exporter um MARCXML zu erstellen. Als erstes wird die Voreinstellung von JSON zu MARCXML geändert und das Prefix wie angegeben eingetragen. Templating können wir für alles nutzen, das nicht nativ im OpenRefine funktioniert.
Aufgabe 1:
Reverse Engineering, was fällt an den Daten auf?
| leader a22 uuu 4500 | hier liegen keine Transformationsregeln vor, ist hart codiert (das bedeutet, dass Text 1:1 übernommen wird, es liegen keine Transformationsregeln vor 1) Fragment von MARC21, das MARCXML eigentlich gar nicht braucht. |
| Im Feld 001 | wird URL ersetzt durch voreingegebenes in Klammer und mit escape (xml) sichergestellt, dass es kein nicht valides XML-Zeichen drin hat, wird dann ersetzt oder gar nicht abgebildet. |
| Im Feld 022 | werden ISSNs eingefügt (escape wird auch genutzt) |
| Im Feld 100 | werden Autorinnen werden bei | getrennt und der allererste wird eingefügt (wiederum mit escape kontrolliert). Dieses Feld ist ohnehin nur für 1 Autorin gedacht |
| Im Feld 245 | wird Titel eingefügt mit escape xml. |
| Im Feld 700 | wir haben for- Funktion, extrahiert (slice) wird alles ab Element 1 (also das erste Element 0 wird weggelassen…) Ergebnisse aus dieser Schleifen-Funktion werden in Variable v geschrieben . Dann hartcodierter Text-String (mit “”) und Variable v wird eingefügt mit escape. |
GREL ist eigene Sprache, allerdings angelehnt an Javascript.
Mit der Erklärung, dass slice(1) das erste Element wegschneidet, hatte ich ziemlich zu kämpfen, da mit dem ersten Element ja eigentlich in der Informatik oft 0 gemeint ist. Ich habe es mir dann folgendermassen erklärt: Ab Index 1 wird alles extrahiert, wodurch das erste Element [0] weggeschnitten wird. So wie ich das verstehe, funktioniert das aber genau so wie Javascript (anders als in der Vorlesung besprochen) und dieses Dokument und das hier erklären das gleich. Ich hoffe also, ich hab das richtig verstanden und ärgere mich, dass ich wieder einmal alles auf den letzten Drücker erledige, so dass ich keine Gelegenheit mehr habe, eine Frage dazu zu stellen.
Übung 2:
Für Übung 2 habe ich nach dem Vorbild von der Library of Congress einen Datensatz versucht zu erstellen. Ich habe mich an der Sprache versucht und folgendes fabriziert:
<datafield tag="041" ind1="0" ind2=" ">
<subfield code="a"></subfield>
</datafield>
Endlich machen für einen MARC21-Neuling wie mich auch die Indikatoren als Attribute Sinn: 0 bedeutet, es handelt sich um keine Übersetzung. Attribute liefern also noch mehr Informationen. Analog verhält es sich mit den Subfieldcodes. So ganz durchschaut hatte ich das bis anhin nicht, macht aber jetzt Sinn.
leere Werte
Es kann Probleme mit dem Template geben, wenn gewisse Zellen keinen Eintrag haben, beispielsweise, wenn ein Datensatz kein Titel hat. Das ergäbe ein leeres XML-Element. Das ist an sich schon nicht so schön und bei bestimmten Abfragen kann es sein, dass leeres Element dann ein technisches NULL erhält. Wenn man Templating-Funktion nutzt, soll dann gezielt Regeln geschaffen werden für leere Zellen oder Zellen mit dem Wert NULL. Zum Beispiel ein leerer String einfügen, wenn Titelfeld leer ist.
-
Danke, dass das erklärt wurde, bin schon gefühlt 100x über diesen Ausdruck gestolpert und habe ihn noch nie so richtig kapiert… ↩