Daemon
Archivesspace ist auch nutzbar, ohne dass die Shell die ganze Zeit im Hintergrund läuft. Archivesspace funktioniert in hierarchischen Prozessen, jeder Prozess hat eine Verbindung zu einem oberen. Wenn man beim Aufrufen am Ende des Befehls ein & anhängt, dann läuft das Programm im Hintergrund.
Internal Server Error im Public Interface
Das Public Interface (8081) ist offenbar noch nicht mit Java 11 kompatibel. Da unter anderem bei mir Java 11 aktiv war, hat das Public Interface zu Beginn nicht funktioniert.
Anzeige der aktuellen Java-Version:
java -version
Aktive Java-Version ändern:
sudo update-alternatives --config java
Es erscheint darauf ein Auswahlmenü zum abändern der Java-Version.
Begrifflichkeiten und Repetition von ArchivesSpace
- Accession: Dokumentation der Erwerbung, ist oft nicht öffentlich, haben wir aber öffentlich gemacht. Wäre im echten Archiv wohl eher unüblich. Oft hat man vertrauliche Angaben, die wir nicht öffentlich machen wollen. Der Erwerbungsprozess soll zwar dokumentiert werden, allerdings wird der Status erst öffentlich gemacht, wenn das Archiv diese Information auch wirklich offen legen will. Das wäre in der Praxis wohl eher am Ende eines Archivierungsprozesses als am Anfang oder mittendrin.
- Gemäss Materialien von NYU dokumentiert die Accession eine Gruppe von Archivmaterial. Eine Collection kann aus einer oder mehreren Accession bestehen und diese sollen die Fragen beantworten, wie das Material zu uns kam, was wir damit gemacht haben und wie wir das Material generell verwalten.
- Resource: in Archivesspace legt man eine Ressource an, die ist zentraler Nachweis auf oberster Ebene von ISAD(G), das kann Nachlass selbst sein oder als Einzelobjekt (beispielsweise Brief oder so ohne Kontext zu anderen Sammlungen). Der Normalfall ist aber, dass wir Nachlass/Sammlung haben usw. und dann das als Resource anlegen.
- Gemäss NYU: Intellektuelle Einheit. Das SAA-Glossar bezeichnet Resource als verfügbare Bestände.
- Archival Object: An dieser Resource kann man dann das sogenannte Archival Object dranhängen. Das ist der Nachweis von Objekten auf weitere Verzeichnisstufen. Sie werden mittels add child an vorhandene Ressourcen angehängt.
Bei einem Archivierungsprozess wird also zuerst eine Accession erstellt, danach eine Resource angehängt und darunter die Archival Objects. Mit diesem Verständnis ist ArchivesSpace auf einen Schlag sehr viel verständlicher und logischer. Bei der Resource kann dann jeweils auch die Verzeichnisstufe nach ISAD(G) angegeben werden.
Gerne hätte ich noch versucht, einen Bestand vollständig nach ISAD(G) aufzunehmen (mit den im letzten Blogpost erwähnten Pflichtfeldern), dies hat aber leider aufgrund der nicht funktionieren Dropdown-Menüs nicht geklappt. Grundsätzlich habe ich aber das Gefühl, dass ich die Theorie und die Tektonik generell genug verstanden habe. Somit habe ich das dann weggelassen und nicht mehr versucht, das ganze beispielsweise in der Demoversion durchzuführen.
Übung Import und Export
Die Aufgabe bestand darin, Beispieldaten im EAD-Format in ArchivesSpace zu importieren und danach wieder zu exportieren.
Als Knackpunkt hat sich (neben “unbrauchbaren” Beständen) das Austauschformat EAD herausgestellt: es ist keine Garantie für problemlose Übernahme von “fremden” Daten. in EAD hat man alles drin, auch die Verzeichnungsstufen, damit das System die auswerten kann, muss aber mehrmals iteriert werden.
Beim Export nach MARCXML bin ich ehrlichgesagt nicht zu bahnbrechenden Erkenntnissen gelangt. Die Verzeichnisstufen werden wohl etwas “geschmälert”, da ich mit MARCXML aber wenig vertraut bin, wäre mir das selber nicht wirklich aufgefallen.
Ich hege aber ja grundsätzlich den Verdacht, dass ArchivesSpace ohnehin nicht will, dass Daten importiert oder exportiert werden, so gut wie die jeweiligen Funktionen versteckt sind…
Alternativen zu ArchivesSpace
ArchivesSpace vor allem in den USA, wird nachhaltig weiterentwickelt. Opensource-Alternative wäre Atom, wobei wir von Karin einen spannenden Einblick erhalten haben. Nicht zu verwechseln mit dem Texteditor von github.
Kommerzielle Verionen: scope archive und CMI STAR. Für Online-Präsentation wird oft noch zusätzliche Software verwendet, beispielsweise e-pics oder e-manuscripta.ch.
Repository-Software für Publikationen und Forschungsdaten
- Open Source: heisst im engeren Sinne tatsächlich offene Software / Quellcode.
- Open Acces: heisst freien Zugang zu Publikationen. Damit ist die ganze Bewegung inklusive politische Positionspapiere gemeint. Daraus entstanden sind Open Access Repositoren. Damit sind meist Publikationen gemeint, nicht Open Data.
- Open Data: Forschungsdaten, plain data, quasi das, was wir im Anhang einer Arbeit erwarten würden. Primärdaten. Allerdings ist der Übergang zwischen Open Access und Open Data fliessend, da Publikationen wiederum Forschungsdaten bedeuten können, beispielsweise in der Literaturwissenschaft.
- Forschungsinformationen: Informationen über Forschende, Drittmittelprojekte, die aquiriert wurde oder über Patente. Alles was nicht Publikation oder Daten ist, wäre Information. Ziel dieser Erhebung ist Forschungsberichterstattung. Es gibt Bemühungen, dass Wissenschaft stärker empirisiert wird. Das Ziel ist es, zu informieren, in welchen Bereichen Wissenschaft stattfindet und diese zu evaluieren.
Beispiele
- Zenodo: Repositry, das Forschungsdaten und Publikationen aufnimmt, wird vom CERN betreut. Vor allem für Physik. Komplett kostenfrei. Man kann gb-weise Daten bereitstellen. Gilt als Best Practice Installation. Das führt zur Frage: Wollen wir Open Access Repository, macht man das wirklich selber oder soll man nicht besser bei Zenodo eine Community bilden? Wenn schlecht gemacht, dann lieber sein lassen und offene Variante nutzen wie Zenodo. Für alles wird eine DOI vergeben, es gibt auch Versionierung. Export in Literaturverwaltungsprogramme und grosse Datenmengen kann man kostenlos hochladen.
- TUHH: Toll ist, dass Infos verknüpft werden können. Man kann über Forschende reingehen und über Person und alles miteinander anschauen. Auch Netzwerkanalyse ist möglich, beispielsweise: Mit wem zusammen schreibt xyz zusammen?
- orcid: ist ein Zusammenschluss von vielen grossen Verlagen mit dem Ziel, Personen aus der Wissenschaft eine eindeutige Identifikationsnummer zu vergeben. Wichtig, weil wenn Personen Einrichtungen verlassen oder Allerweltsnamen haben, will man das der Person trotzdem zuordnen können. Man kann sich registrieren und erhält persönliche orcid-Identifikationsnummer.
DSpace
Dspace ist eine Software, die sich sowohl für Publikationen als auch für Forschungsdaten eigenet. Möchte man sie für Forschungsinformationen nutzen, gibt es die Erweiterung DSpace-CRIS.
Übungen
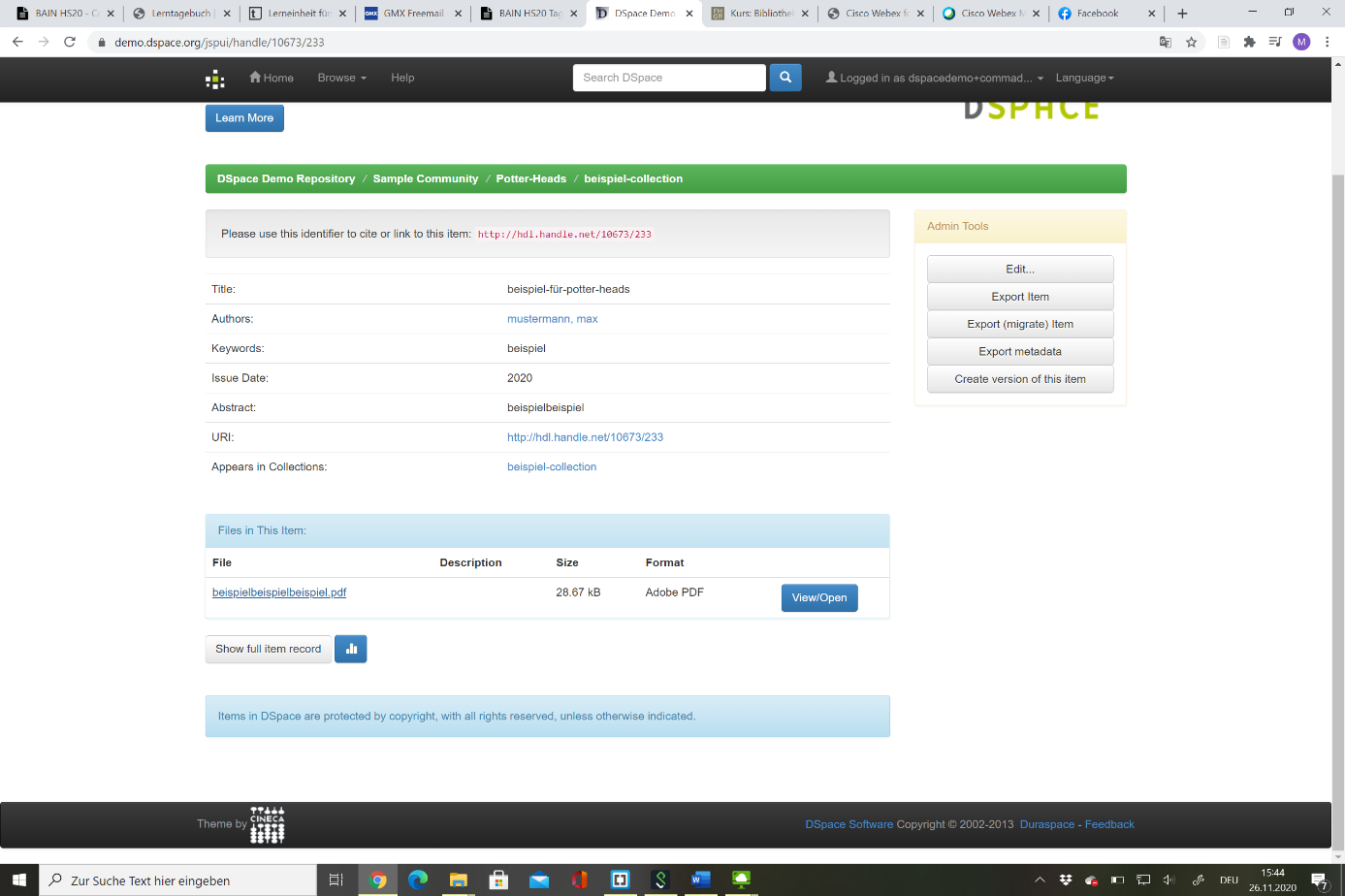
Die Übung bestande darin, eine Sub-Community und darin eine Collection anzulegen. Community wäre beispielsweise “FH Graubünden” und die Collcection “Studentische Arbeiten”. Dies hängt wohl mit dem Rechtemanagement zusammen, denn in der Community wird festgelegt, wer die zugehörigen Collections verwalten darf. Das möchte man nur an einer Stelle machen und nicht bei jeder Collection. Zudem können wohl ganze Communities “geharvestet” werden, also Daten über eine Schnittstelle abgefragt werden.
Meine Subcommunity Potter-Heads wurde um die Collection beispiel-collection reicher und enthält das Dokument beispiel.pdf, verfasst von Max Mustermann.